
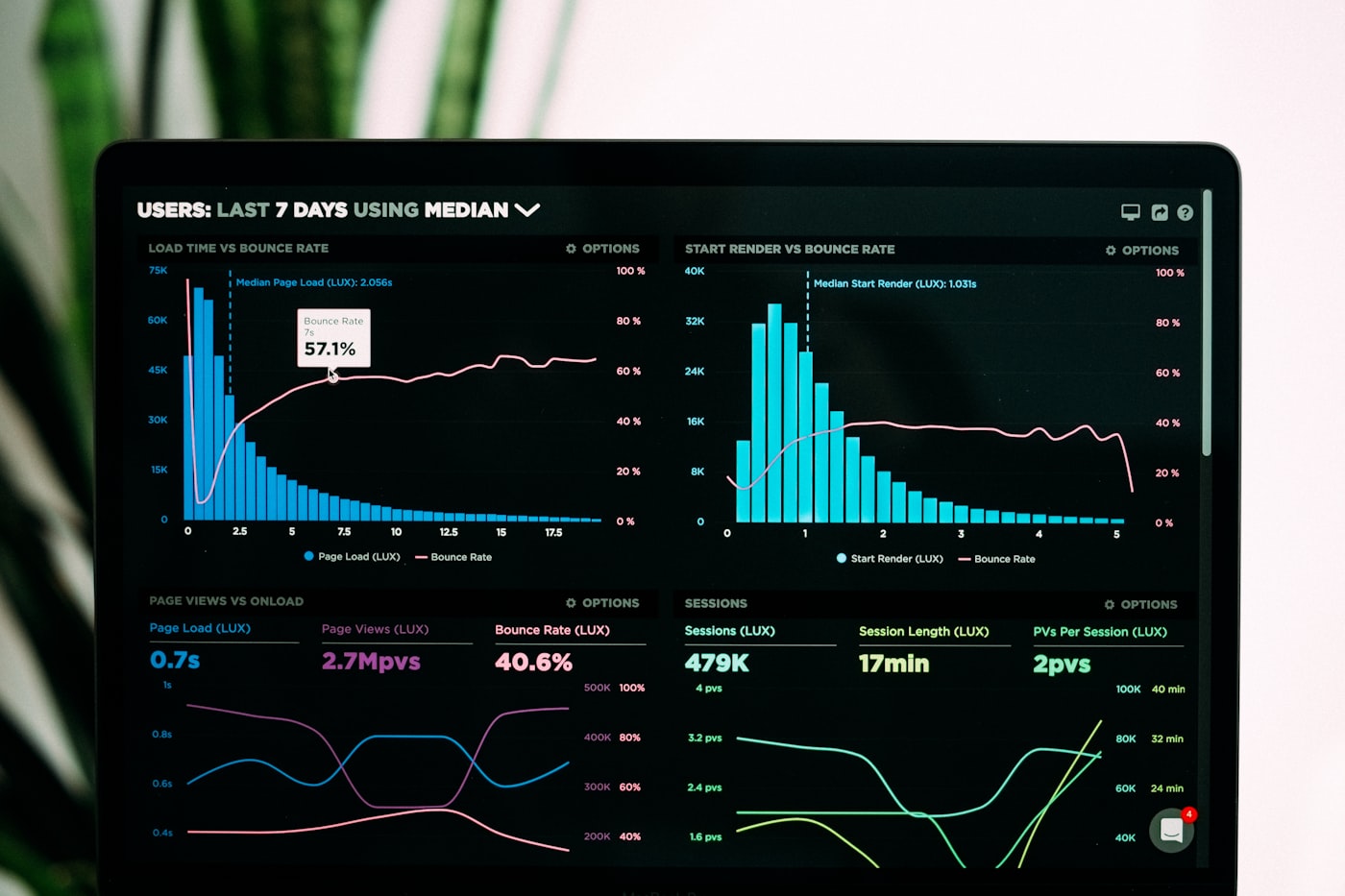
A table can list two measurements side by side, but it may not show their relationship very clearly. A scatterplot turns each pair of numbers into a point, letting the whole pattern appear at once. That makes it one of the most useful graphs for questions such as whether taller plants also have wider leaves, whether more practice time is connected with better free-throw accuracy, or whether warmer days bring higher electricity use.
The basic idea is simple: one variable goes on the horizontal axis, the other goes on the vertical axis, and every point represents one observation. If a student studied for 3 hours and scored 82, the point is placed where 3 and 82 meet. After many points are added, the graph may show an upward pattern, a downward pattern, a cloud with no clear direction, separate clusters, or one unusual value sitting far away from the rest. The skill is not just making the graph. It is learning what the pattern can and cannot tell you.
What Each Point Represents
A scatterplot works with paired data, also called bivariate data. Each point must come from the same case, person, place, event, or measurement period. If the graph compares height and arm span, each point should use one person’s height and that same person’s arm span. If the graph compares daily temperature and ice cream sales, each point should use the temperature and sales from the same day.
That pairing is what gives the graph meaning. If the x-values and y-values are shuffled separately, the points may still fill the graph, but the relationship has been broken. A scatterplot is not just two lists of numbers; it is a map of how two measurements travel together in real situations.
The axes need careful attention. The horizontal axis, often called the x-axis, usually holds the explanatory variable or the variable chosen as the starting point for comparison. The vertical axis, or y-axis, usually holds the response variable. For example, if a class is looking at hours practiced and typing speed, hours practiced might go on the x-axis and typing speed on the y-axis. That arrangement does not prove practice causes speed to improve, but it matches the question being asked.

Direction, Form, and Strength
The first thing to notice in a scatterplot is direction. A positive association slopes upward from left to right: larger x-values tend to come with larger y-values. A negative association slopes downward: larger x-values tend to come with smaller y-values. If the points do not lean clearly upward or downward, the graph may show little or no association.
Direction is only the beginning. The form of the pattern matters too. Some relationships are roughly linear, meaning the points gather around a straight path. Others are curved. A plant may grow faster as it receives more light up to a point, then level off when extra light no longer helps much. A straight trend line would miss part of that story because the relationship changes shape across the graph.
Strength describes how tightly the points follow the pattern. If most points sit close to an upward-sloping line, the positive relationship is strong. If the points lean upward but spread widely, the relationship is weaker. A weak relationship can still be real and useful, especially in human behavior, weather, health, and economics, where many factors act at the same time. But a wide scatter should make a reader cautious about making precise predictions from the graph.
A helpful reading routine is to say all three features together: direction, form, and strength. Instead of saying only “the graph goes up,” say, “The scatterplot shows a moderately strong positive linear association.” That wording is not fancy decoration. It separates what the graph actually shows from what a reader might be tempted to assume.
Clusters and Outliers Tell Their Own Story
Scatterplots are especially good at revealing details that a single number can hide. A cluster is a group of points gathered in one part of the graph. Clusters may show that the data contains different groups. A graph of commute time and distance, for example, might show one cluster for walkers and cyclists, another for drivers, and another for train riders. If those groups are mixed together without explanation, the overall pattern may be confusing.
An outlier is a point that sits far away from the main pattern. Outliers deserve attention, but they should not automatically be thrown away. A point may be far from the others because of a measurement error, a typo, or a mismatched unit. It may also be a real case that teaches something important. A school with unusually strong reading growth, a city with unusually low water use, or a team with an unexpected scoring record may be worth studying precisely because it does not fit the pattern.
Clusters and outliers can change the way a trend line looks. One extreme point can pull a line upward or downward, especially when the data set is small. That is why a scatterplot should be inspected before any summary is trusted. The graph gives the reader a chance to ask whether the summary describes most of the data or has been bent by a few unusual points.
Statistician Francis Anscombe made this point memorable in 1973 with a set of four small data sets now called Anscombe’s quartet. The four sets have nearly identical summary statistics, including the same mean values and correlation, but their scatterplots look very different. One shows a clean line, another shows a curve, another depends heavily on an outlier, and another has most points stacked vertically with one unusual value. The lesson is clear: a calculation can be correct and still fail to show the shape of the data.
What a Line of Best Fit Can and Cannot Do
When a scatterplot has a roughly linear pattern, a line of best fit can summarize the trend. The line is placed so it runs through the middle of the cloud of points as fairly as possible. It does not need to pass through every point. In real data, it usually will not. Its job is to show the general direction and rate of change.
The slope of the line gives the approximate change in y for each one-unit increase in x. If a trend line for practice time and typing speed has a slope of 4, that might mean each extra hour of practice is associated with about 4 more words per minute, on average. The phrase “on average” matters. Individual points may sit above or below the line because people differ, conditions differ, and measurements are never perfectly tidy.
A line of best fit can help with interpolation, which means estimating a value inside the range of the data. If the graph includes practice times from 1 to 6 hours, estimating the value at 4 hours may be reasonable if the pattern is strong enough. Extrapolation is riskier. That means using the line to predict outside the range of the data, such as guessing what would happen after 20 hours of practice when no one in the data practiced more than 6. Patterns often change beyond the measured range.
A trend line also does not prove cause and effect. If two variables move together, one may influence the other, but a third variable may be shaping both. A scatterplot can suggest a question worth investigating; it cannot answer every why question by itself. Strong causal claims need better evidence, such as careful study design, comparison groups, timing, and a plausible explanation for how one variable affects the other.
Common Mistakes When Reading Scatterplots
One common mistake is ignoring the scale. A graph can look dramatic if the axes are narrow, or flat if the axes are wide. Before interpreting the pattern, check the numbers on both axes and notice whether the scale starts at zero, uses equal intervals, or cuts off part of the range. Scatterplots do not always need to start at zero, but the axis choices should be read carefully.
Another mistake is focusing only on the trend and missing the spread. Two scatterplots can have the same upward direction but very different usefulness for prediction. If points are tightly packed around the line, a prediction from the line may be fairly informative. If points are scattered widely, the line may show a general tendency while still leaving a large amount of uncertainty.
A third mistake is treating every point as equally reliable. Real data can contain errors, estimates, repeated measurements, missing values, or cases collected under different conditions. If a scatterplot uses survey data, the way the survey was asked may matter. If it uses science measurements, the instrument and method may matter. If it uses school or city data, group averages may hide differences inside each group.

How Scatterplots Build Better Data Habits
Scatterplots are useful because they slow down the rush from numbers to conclusions. They let readers see whether a relationship is positive or negative, straight or curved, tight or loose, simple or broken into groups. They also reveal when an unusual point deserves a closer look. Those habits matter in school assignments, science reports, sports analysis, public health charts, economics stories, and everyday claims built from data.
A good scatterplot reading begins with a plain description before interpretation. What are the variables? What does one point represent? What direction, form, and strength appear? Are there clusters or outliers? Would a line of best fit make sense, or would a different kind of graph explain the data better? These questions keep the reader grounded in evidence.
The best scatterplots do not make data feel smaller. They make it easier to think about. A point pattern can show a relationship that a table buries, but it can also show why a simple summary is not enough. Once the pattern is visible, the next step is clearer: describe what the graph shows, ask what might explain it, and be honest about what the data still cannot prove.




Add comment